> ## Chapter8-2.고객들은 정말로 만족하였을까? (감성 분석)
>
> # 사전 파일을 불러오기 위한 라이브러리 불러오기
> library(readr)
> # 이미 만들어진 리뷰 감성분석 전용 사전을 불러옴
> rev <- read_delim("review_dict.txt", delim="\t", col_names=c("word", "score"))
-- Column specification ----------------------------------------------------------------------------------------------------
cols(
word = col_character(),
score = col_double()
)
>
> head(rev, 10)
# A tibble: 10 x 2
word score
<chr> <dbl>
1 감사합니다 2
2 고생했네요 -2
3 이하네요 -2
4 끝내 주네요 2
5 기가막히게 1
6 늦었네요 -2
7 만족합니다 2
8 만족해요 2
9 맛은 있네요 1
10 맛있게 2
>
> # 감성분석을 위한 패키지 설치
> install.packages("SentimentAnalysis")
> library(SentimentAnalysis)
>
> # sd에 감성분석 전용 사전의 단어에 따른 점수로 가중치를 매길 수 있게 기준 설정
> sentdic <- SentimentDictionaryWeighted(words = rev$word,
+ scores = rev$score)
>
> # 점수가 0보다 크면 긍정어(positive), 0보다 작으면 부정어(negative)로 기준 설정
> sentdic <- SentimentDictionary(rev$word[rev$score>0],
+ rev$word[rev$score<0])
>
> # 감성사전 기준 확인
> summary(sentdic)
Dictionary type: binary (positive / negative)
Total entries: 57
Positive entries: 32 (56.14%)
Negative entries: 25 (43.86%)
>
> # 미리 크롤링 해놓은 ch8.txt 파일을 txt에 저장함
> txt <- readLines("ch8.txt", encoding = "UTF-8")
>
> # gsub 함수 대신 이번엔 stringr 패키지를 통해 텍스트 대체 실시
> library(stringr)
>
> # 마침표, 쉼표, 느낌표, 물음표를 다 없앰
> txt_2 <- str_replace_all(txt, "([.,!?])","")
> head(txt_2)
[1] "닭이 너무 맛있어요 최고 육질이 살아있음" "배송도 빠르고 상품도 좋습니다 ^^"
[3] "기가막히게 맛있습니다 사장님 감사합니다" "닭이 너무 작아요 양이 작은 편인데도 부족하네요 ><"
[5] "완전 만족합니다 재구매 각이네요" "삼계탕에 넣었는데 양이 기대 이하네요"
>
> # txt_2 데이터 타입 확인
> class(txt_2)
[1] "character"
>
> # 문서형 데이터 형태 변환을 위해 tm 라이브러리 불러오기
> library(tm)
>
> # txt_2 데이터를 Corpus 형태로 변환
> co_txt <- Corpus(VectorSource(txt_2))
> class(co_txt) # 데이터 타입 확인
[1] "SimpleCorpus" "Corpus"
>
> inspect(co_txt) # co_txt 형태 살펴보기
<<SimpleCorpus>>
Metadata: corpus specific: 1, document level (indexed): 0
Content: documents: 30
[1] 닭이 너무 맛있어요 최고 육질이 살아있음
[2] 배송도 빠르고 상품도 좋습니다 ^^
[3] 기가막히게 맛있습니다 사장님 감사합니다
[4] 닭이 너무 작아요 양이 작은 편인데도 부족하네요 ><
[5] 완전 만족합니다 재구매 각이네요
...
[30] 아직 요리는 안해 봤는데 겉모습은 마트에서 파는 닭과 별 차이를 못 느끼겠습니다 맛있겠죠
>
> # Corpus 형태에서 DocumentTermMatrix 형태로 변환
> dtm_txt <- DocumentTermMatrix(co_txt)
>
> # DocumentTermMatrix 형태 살펴보기
> inspect(dtm_txt)
<<DocumentTermMatrix (documents: 30, terms: 214)>>
Non-/sparse entries: 268/6152
Sparsity : 96%
Maximal term length: 7
Weighting : term frequency (tf)
Sample :
Terms
Docs 건지 것 너무 닭이 만족해요 먹었습니다 양이 작은 잘 큰
11 1 0 1 0 0 0 0 0 2 0
14 0 0 1 1 0 0 0 0 0 0
15 1 0 1 0 0 1 0 0 1 0
16 0 0 1 0 0 1 1 1 1 0
20 0 0 0 0 0 0 0 0 0 1
22 0 0 0 0 0 0 1 0 0 1
27 0 1 0 0 0 0 0 0 1 0
30 0 0 0 0 0 0 0 0 0 0
8 0 0 0 1 0 0 0 0 0 1
9 0 0 0 1 0 0 0 0 0 0
>
> # (참고)특정 문서와 특정 단어순서들을 지정해서 검색할 수도 있음
> inspect(dtm_txt[2,1:9])
<<DocumentTermMatrix (documents: 1, terms: 9)>>
Non-/sparse entries: 3/6
Sparsity : 67%
Maximal term length: 4
Weighting : term frequency (tf)
Sample :
Terms
Docs 너무 닭이 맛있어요 배송도 빠르고 살아있음 상품도 육질이 최고
2 0 0 0 1 1 0 1 0 0
>
> # dtm_txt를 위에서 만든 감성 기준 사전 sentdic을 이용해 분석
> res <- analyzeSentiment(dtm_txt, language="korean",
+ rules=list("sentiment"=list(ruleSentiment, sentdic)))
> # 결과확인
> head(res)
sentiment
1 0.3333333
2 0.5000000
3 0.7500000
4 -0.4285714
5 0.5000000
6 -0.2000000
>
> # sentiment가 0보다 크면 긍정, 0이면 중립, 0보다 작으면 부정으로 표시
> res$pn <- ifelse(res$sentiment>0,"Positive",
+ ifelse(res$sentiment==0,"Neutral","Negative"))
> head(res)
sentiment pn
1 0.3333333 Positive
2 0.5000000 Positive
3 0.7500000 Positive
4 -0.4285714 Negative
5 0.5000000 Positive
6 -0.2000000 Negative
>
> # 결과 요약해서 보기
> table(res$pn)
Negative Neutral Positive
13 4 13
>
> # 결과 별도 저장하되 데이터 프레임 형태로 변환
> df_res <- as.data.frame(table(res$pn))
>
> # 데이터 프레임 열이름 별도 지정
> names(df_res) <- c("res","freq")
>
> # 파이차트에 퍼센트 표시를 위해 pct 열 생성
> df_res$pct <- round(df_res$freq/sum(df_res$freq)*100, 1)
> df_res
res freq pct
1 Negative 13 43.3
2 Neutral 4 13.3
3 Positive 13 43.3
>
> # 파이차트로 감성 분석 결과 확인하기
> pie(df_res$freq, labels = paste(df_res$res, df_res$pct, "%"),
+ main = "생닭 판매 고객 리뷰 감성 분석 결과")
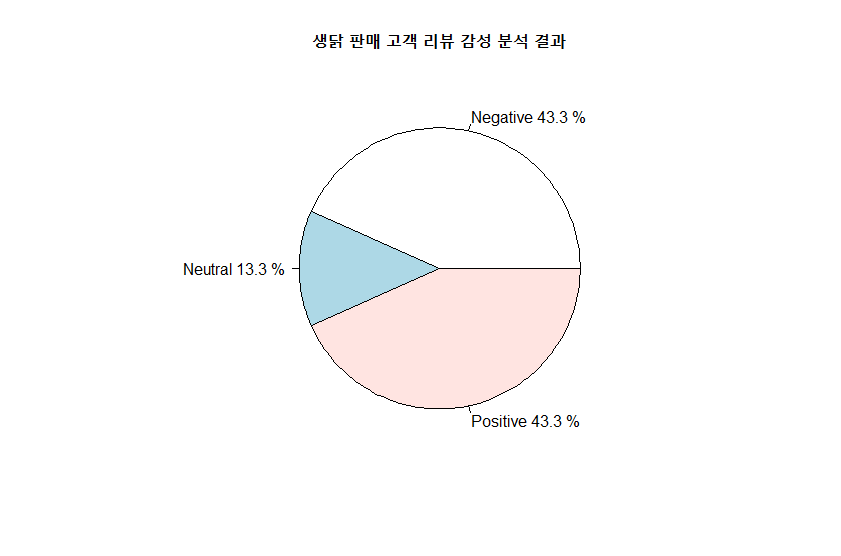
출처 : 현장에서 바로 써먹는 데이터 분석 with R
'데이터분석 > R' 카테고리의 다른 글
| [R 데이터분석 with 샤이니] - 전처리 : 데이터를 알맞게 다듬기 (0) | 2022.07.02 |
|---|---|
| [R 데이터분석 with 샤이니] 자료 수집 : API 크롤러 만들기 (0) | 2022.06.29 |
| [현장에서 바로 써먹는...] 텍스트마이닝 - 워드클라우드 (0) | 2022.05.02 |
| 타이타닉 데이터 분류 예측 (0) | 2022.04.25 |
| [현장에서 바로 써먹는...] 인공 신경망과 딥러닝 - 분류 (0) | 2022.04.16 |



